Dec 9, 2006
Bangladeshi men are more studly
Just ask Malaysian ladies: http://news.bbc.co.uk/2/hi/business/4802796.stm.
Dec 7, 2006
Programming kids
Sometimes when I'm teaching kids at my mom's tutorial, I get this feeling that teaching a kid something is a lot like programming a computer.
The objective when I'm teaching is to get some concept across to the kid, so he can grasp it and manipulate it in his mind. With a computer, you want to instruct it to perform a certain task. So with this kid, you have to find a way to get the concept across, and the technique I use most often is to break it down into simpler parts which can be easily understood. E.g. to explain the concept of a conjunction (one of the parts of speech) to a kid in class 4, I would give an example of two short sentences, side by side, then show a conjunction which joins them together:
I ran. They walked.
Conjunction: but
Result: I ran, but they walked.
(I often use mnemonics too, like conJunctions are Joining words -- the `J' is the mnemonic; but that's not really relevant for computers.)
Anyway, with a computer, you break down a task, say changing the screen saver, into simple parts like: get the screen saver file name to use -- maybe from the user, or from some text file in the computer; access the Windows registry; put the new screen saver's file name into the right place in the registry; save and close the registry.
Now here is where it gets interesting. The first time round, it's almost a given that you won't get the concept across properly, and the kid will be in some kind of confusion about what you're saying. Same with a computer. It's almost certain there's a mistake in the program somewhere -- a bug. So you have to debug. This is an interactive process where you try to find out what's wrong by querying the kid/computer about what they think is going on, then you reprogram/re-instruct to compensate for that.
So, the kid says he doesn't understand the conjunction thing. The debugging always starts with making sure he knows the context that we're discussing this in; I have to make sure he knows that we need some words in the language to join sentences together to convey more information easily. (Otherwise we're forever stuck with extremely simple, one-verb sentences, each of which conveys maddeningly tiny amounts of information.)
In simple concepts like conjunctions, clarifying the context should clear up about 75% of the problems; but the more complicated the concept -- say, teaching the rules of algebra to a class 5 kid -- the more I have to go, step by step, into the parts which make up the overall concept: variables are unknowns; constants are knowns; variables and constants make up equations; equations can be solved to find the unknown by putting it alone on the left hand side; this is achieved by performing the same arithmetic operation to both sides of the equation, keeping both sides equal, and continuing until the unknown is alone on the left hand side.
For each of the above steps, I have to explain its purpose (context) -- i.e., what problem does it solve? Then I have to make sure the kid knows how to do it, and lastly of course, what to do if things don't turn out like expected. The same thing happens with computers, except of course they have no sense of context, nor do they need it. They simply perform one simple task after the other, in sequence, until the more complicated job is done. And unexpected outcomes are handled using a combination of the programming language and libraries of reusable code -- they're generally called error handling or exception handling (as in, exceptional cases).
Of course, all of the above is the ideal case when teaching a kid. The reality is I'm going to run out of time before I can properly explain the whole thing, or the kid is going to get incredibly bored and start drifting off to sleep. Maybe I can take a break then.
The objective when I'm teaching is to get some concept across to the kid, so he can grasp it and manipulate it in his mind. With a computer, you want to instruct it to perform a certain task. So with this kid, you have to find a way to get the concept across, and the technique I use most often is to break it down into simpler parts which can be easily understood. E.g. to explain the concept of a conjunction (one of the parts of speech) to a kid in class 4, I would give an example of two short sentences, side by side, then show a conjunction which joins them together:
I ran. They walked.
Conjunction: but
Result: I ran, but they walked.
(I often use mnemonics too, like conJunctions are Joining words -- the `J' is the mnemonic; but that's not really relevant for computers.)
Anyway, with a computer, you break down a task, say changing the screen saver, into simple parts like: get the screen saver file name to use -- maybe from the user, or from some text file in the computer; access the Windows registry; put the new screen saver's file name into the right place in the registry; save and close the registry.
Now here is where it gets interesting. The first time round, it's almost a given that you won't get the concept across properly, and the kid will be in some kind of confusion about what you're saying. Same with a computer. It's almost certain there's a mistake in the program somewhere -- a bug. So you have to debug. This is an interactive process where you try to find out what's wrong by querying the kid/computer about what they think is going on, then you reprogram/re-instruct to compensate for that.
So, the kid says he doesn't understand the conjunction thing. The debugging always starts with making sure he knows the context that we're discussing this in; I have to make sure he knows that we need some words in the language to join sentences together to convey more information easily. (Otherwise we're forever stuck with extremely simple, one-verb sentences, each of which conveys maddeningly tiny amounts of information.)
In simple concepts like conjunctions, clarifying the context should clear up about 75% of the problems; but the more complicated the concept -- say, teaching the rules of algebra to a class 5 kid -- the more I have to go, step by step, into the parts which make up the overall concept: variables are unknowns; constants are knowns; variables and constants make up equations; equations can be solved to find the unknown by putting it alone on the left hand side; this is achieved by performing the same arithmetic operation to both sides of the equation, keeping both sides equal, and continuing until the unknown is alone on the left hand side.
For each of the above steps, I have to explain its purpose (context) -- i.e., what problem does it solve? Then I have to make sure the kid knows how to do it, and lastly of course, what to do if things don't turn out like expected. The same thing happens with computers, except of course they have no sense of context, nor do they need it. They simply perform one simple task after the other, in sequence, until the more complicated job is done. And unexpected outcomes are handled using a combination of the programming language and libraries of reusable code -- they're generally called error handling or exception handling (as in, exceptional cases).
Of course, all of the above is the ideal case when teaching a kid. The reality is I'm going to run out of time before I can properly explain the whole thing, or the kid is going to get incredibly bored and start drifting off to sleep. Maybe I can take a break then.
Nov 22, 2006
Finally managed to learn C#
And it wasn't as hard as I thought it would be. I finally dove into the Ecma C# language specification document, for lack of any better reference/tutorial books here in Dhaka, and went through it absorbing everything that had confused me about the language before (like attributes, the override keyword and inheritance, assemblies and DLLs). A little bit about that spec. I downloaded it a long time ago meaning to go through it and learn the language, but kept putting it off. Now that I've done it, I see the spec is really an excellent reference for learning the language -- probably better than any O'Reilly `In a Nutshell' book for the language. If you're not new to programming, but are new to C#, just get it. It's worth it.
Wish there was an equivalent .NET library reference though. The MSDN library is very thorough but also bloated and slow. Kinda typical of Microsoft when you think about it. Heh, heh.
To celebrate, here's the first useful program I wrote (just now) in C#: ToggleScreenSaver. It's a command-line tool that turns your screen saver on or off. Works only on Windows. Usage is:
ToggleScreenSaver [on|off]
on: turns the screen saver on
off: turns it off
Source code:
Wish there was an equivalent .NET library reference though. The MSDN library is very thorough but also bloated and slow. Kinda typical of Microsoft when you think about it. Heh, heh.
To celebrate, here's the first useful program I wrote (just now) in C#: ToggleScreenSaver. It's a command-line tool that turns your screen saver on or off. Works only on Windows. Usage is:
ToggleScreenSaver [on|off]
on: turns the screen saver on
off: turns it off
Source code:
// ToggleScreenSaver.cs
using System;
using Microsoft.Win32;
public class ToggleScreenSaver {
static void Main(string[] args) {
// args[0] is the first argument passed and so on, not the name of the program
// That's a little brain-dead, but OK, we can roll with it
RegistryKey rk = Registry.CurrentUser.OpenSubKey("Control Panel\\Desktop", true);
if (args[0] == "on") {
rk.SetValue("ScreenSaveActive", "1");
} else {
rk.SetValue("ScreenSaveActive", "0");
}
rk.Close();
}
}
Oct 29, 2006
Some interesting tweaks for Firefox
For when I get around to installing it:
(This is from the Slashdot article Firefox 2 Downloads Top 2 million in 24 hours.)
(This is from the Slashdot article Firefox 2 Downloads Top 2 million in 24 hours.)
Here are some of the settings that I've gathered so far to get Firefox 2.0 to my liking:
In about:config
* browser.tabs.closeButtons to 3 for one close tab button
* browser.tabs.selectOwnerOnClose to false for successive reading and closing
* browser.tabs.tabminwidth to 20 for displaying tab scrolling in extreme cases only
* browser.urlbar.hideGoButton no use for the Go button
* dom.disable_window to true, fix various window annoyances
* network.prefetch-next to false for not wasting my bandwidth
In userChrome.css for disabling the List all tabs which annoys me when using the close button:
/* Disable Container box for "List all Tabs" Button */
.tabs-alltabs-stack {
display: none !important;
}
Feel free to add your own to the thread.
In about:config
* browser.tabs.closeButtons to 3 for one close tab button
* browser.tabs.selectOwnerOnClose to false for successive reading and closing
* browser.tabs.tabminwidth to 20 for displaying tab scrolling in extreme cases only
* browser.urlbar.hideGoButton no use for the Go button
* dom.disable_window to true, fix various window annoyances
* network.prefetch-next to false for not wasting my bandwidth
In userChrome.css for disabling the List all tabs which annoys me when using the close button:
display: none !important;
}
Feel free to add your own to the thread.
Oct 27, 2006
LaTeX document fidelity
Here's something I've been meaning to talk about. Came across this comment in an MSDN blog yesterday. The blogger, Rick Schaut, is a software design engineer for Microsoft Word on the Mac. He makes the following claim:
And of course, unless I'm missing something here, any plain LaTeX source files will compile to the exact same PDF file whether it's on Windows or the Mac; that's a given, because the processing that TeX applies to the source file is the same regardless of operating system.
Of course, there is the entirely separate issue of distributing LaTeX source files or DVI files of your documents; but given all the potential incompatibilities you can face there, why even bother to distribute anything other than PDFs? LaTeX + PDF is the only sane way to go.
To relate this back to the equation editing problem, the problem with any TeX-based way is that you won't get identical layout from one platform to another. TeX (whichever flavor you're talking about) is designed to maximize the quality of the output for each given platform, but that sacrifices some aspects of layout compatibility.Here, Mr Schaut, you are happily wrong :-) TeX and LaTeX cleverly outsource the work of device- and operating system-independent document rendering; they merely specify the document's internal structure. Once a TeX processing system has turned the document into a PostScript or PDF file, you can merrily distribute it anywhere you want with full assurance that the rendering will be inviolate, down to the last full stop on the last line of each paragraph.
Suppose, for example, you have two people working on a paper. One uses a Windows computer, the other uses a Macintosh. Should that paper include a rather lengthy equation, there's a good chance that the equation might fit on one line when the document is opened on the Mac yet not fit on one line when the document is opened on the Windows computer.
And of course, unless I'm missing something here, any plain LaTeX source files will compile to the exact same PDF file whether it's on Windows or the Mac; that's a given, because the processing that TeX applies to the source file is the same regardless of operating system.
Of course, there is the entirely separate issue of distributing LaTeX source files or DVI files of your documents; but given all the potential incompatibilities you can face there, why even bother to distribute anything other than PDFs? LaTeX + PDF is the only sane way to go.
Oct 25, 2006
Temptation, thy name is Internet Explorer 7
OK, I know I said I'd upgrade to IE7 later, but I seriously couldn't resist the temptation -- especially since I have nothing to lose by upgrading now; IE is not my default browser and I'm not using anything that might not be ready for the upgrade. So how am I finding it?
Internet Explorer 7 feels much better than 6. Tab support is awesome, and rather faster than it was before, although still not as fast as Firefox's. And the keyboard shortcuts for switching among tabs should definitely be simpler than Ctrl-Tab and Ctrl-Shift-Tab -- they should really be Ctrl-PgDown and Ctrl-PgUp like they are in Firefox. That said, I've just discovered the Quick Tabs feature (shortcut: Ctrl-Q), which may just be the best tab-related feature I've seen yet in a browser. Press the key and IE shows a tab containing thumbnail previews of each of your tabs, and you can go to the tab you want with a single click. This is amazingly fast, and really cool.
Everything else they've done, including getting rid of the menu bar and putting the the address bar right below the title bar along with the navigation buttons, I applaud because it just increases the screen viewing space in the browser. Who uses the menus in their browser all that much, anyway? And if you need it, you can just right-click on any toolbar and turn it on. Or just press the Alt key to turn it on temporarily.
IE still doesn't have extension manager as convenient as the one in Firefox, but that's OK, I've invested a lot in Firefox, including future plans with Greasemonkey; and I wouldn't really switch back to IE even if it had awesome extensions. (Well, maybe if they had a Greasemonkey-compatible extension....)
So to conclude? IE7 feels like a hit. Definitely go for it. But as for Firefox 2? I've dowloaded the installer, but I'll still wait out the couple of weeks to get it through Mozilla's updating channels once they've made sure all the best extensions are compatible with it.
Internet Explorer 7 feels much better than 6. Tab support is awesome, and rather faster than it was before, although still not as fast as Firefox's. And the keyboard shortcuts for switching among tabs should definitely be simpler than Ctrl-Tab and Ctrl-Shift-Tab -- they should really be Ctrl-PgDown and Ctrl-PgUp like they are in Firefox. That said, I've just discovered the Quick Tabs feature (shortcut: Ctrl-Q), which may just be the best tab-related feature I've seen yet in a browser. Press the key and IE shows a tab containing thumbnail previews of each of your tabs, and you can go to the tab you want with a single click. This is amazingly fast, and really cool.
Everything else they've done, including getting rid of the menu bar and putting the the address bar right below the title bar along with the navigation buttons, I applaud because it just increases the screen viewing space in the browser. Who uses the menus in their browser all that much, anyway? And if you need it, you can just right-click on any toolbar and turn it on. Or just press the Alt key to turn it on temporarily.
IE still doesn't have extension manager as convenient as the one in Firefox, but that's OK, I've invested a lot in Firefox, including future plans with Greasemonkey; and I wouldn't really switch back to IE even if it had awesome extensions. (Well, maybe if they had a Greasemonkey-compatible extension....)
So to conclude? IE7 feels like a hit. Definitely go for it. But as for Firefox 2? I've dowloaded the installer, but I'll still wait out the couple of weeks to get it through Mozilla's updating channels once they've made sure all the best extensions are compatible with it.
Eid mubarak
Eid day yesterday was great. I think Bangalis really know how to turn in a good Eid party, if they're in the mood. Some friends got hold of a Bangladeshi biryani chef, who cooked us a big pot of awesome chicken biryani. We got together at their place and had a good lunch, and a nice break from the pressure of the upcoming exams. I know there's a risk of all these breaks from the pressure turning into a permanent break from studies -- but hopefully we'll keep things under control here.
Firefox 2 & Internet Explorer 7
Firefox 2 is coming out in a few hours, but I'm really very satisfied with 1.5. I read though that 1.5 will soon have a minor update that paves the way for an automatic update to version 2, in a couple of weeks. I'm taking that upgrade strategy, because I'm a little worried that my current extensions, especially the very useful SessionSaver extension, will need some time to adapt properly to FF2. So hopefully in a couple of weeks that will be the case. But I'll probably wait a wee bit more even then while checking up on their status, i.e. what people have to say about them.
Not to sound nostalgic, but it seems like just yesterday that I downloaded the all-new Internet Explorer 5 over my slow dial-up line in Sharjah and tried it out, after reading a glowing review full of lavish screenshots in the Emirates' Windows User Magazine. And it was an awesome browser, the best of the best after using Netscape's weird-looking offering. But yeah, anyway ... IE7 is out now, and I know I'm going to upgrade. But similarly to Firefox, I'll wait till Microsoft pushes IE7 out to us through its Windows Update facility -- it gives everyone some breathing room and just feels right.
I won't really be using IE7 -- not with FF2 probably installed by then -- but obviously, it will be necessary to have it because of the bugfixes and interesting new features to try out.
It strikes me now that in about a couple of weeks, I'll be flying back to Dhaka, where my laptop will be totally cut off from internet access -- our desktop PC in Dhaka is the only machine which will be connected (hopefully, anyway). So it might be more than a month before any software gets upated on the laptop. That's fine by me, I guess. I'll still be able to try out FF2 on the home desktop. Hm, might download it now and take it to Dhaka to install, to save the download hassle when I get there.
Oct 20, 2006
Bayesian multi-category classification in Gmail?
What this would do is something like what POPFile does for email clients like Thunderbird or Outlook or whatever: automatically categorise incoming emails based on keywords they contain. POPFile is trainable and it's supposed to reach a pretty high accuracy after a couple of weeks. POPFile doesn't actually put your emails into different folders in your email program; it just marks them as belonging to one category or other (say `Work', `Family', `Junk', `Stamp collecting', etc.). Then you set up your email program so that it puts these emails into different folders, or deletes them, or forwards them, or whatever.
What POPFile does
OK first of all, you're asking why would you want some software like POPFile to classify emails for you when you can just set up filters in your email program to do that based on who they're from, what the subject is, and so on? The reason is your email client's filters are static: they do not learn about new family members who are sending you email, nor about new correspondents from your workplace, nor about new junk mailers you have to deal with all the time. In fact, programs like Thunderbird already have Bayesian filtering to deal with this problem of continually-changing junk mails -- it's just that POPFile goes one step further, to try to identify your mails as belonging to arbitrary categories that you set up.
The idea is, once you've set up POPFile to recognise email from your family, from your work, and from your stamp collecting buddies, it will correctly identify these different types of emails, say, about 99.99% of the time. The rest of the time, which is presumably a piffling amount of time, you'll be telling POPFile something like `no, this isn't junk, it's just my little brother, mark it as ``Family'' '. And POPFile will continue to learn, using the Bayesian statistical analysis.
So the end result is, you can set up your email programs to put email marked `Work' in the right folder, and so on, without having to worry about updating your filters all the time.
Now here's my question: why should email program users get these benefits exclusively? Why can't we have something like this for webmail users? Specifically, Gmail users (like me, and it seems half the world nowadays)? Maybe we can. It boils down to three things: Gmail's JavaScript functions, POPFile's statistical categorisation methods, and Firefox's Greasemonkey extension.
What Greasemonkey does
Basically, Greasemonkey allows you to customise Web pages in Firefox in almost unlimited ways with a little JavaScript programming, using that page's Document Object Model and any JavaScript functions defined in it. Check out http://persistent.info/archives/2005/03/01/gmail-searches for an idea about just how powerful Greasemonkey is, and what it can do to Gmail.
I've tried out the above hack, and it actually does work, with a few hiccups. Furthermore, I've tried programming Greasemonkey scripts myself and I can tell you it's a really powerful way of customising websites which you love to make them even more useful. There are actually a ton of scripts people have written out there, and the best place to get them is userscripts.org. Check it out.
POPFile for Gmail?
OK, now we know we can extend Gmail's functionality in amazing ways with Greasemonkey hacks like the one above. Essentially, Greasemonkey is giving us the means to program a user interface for the new Bayesian classification classification features we want in Gmail. Greasemonkey scripts are written in JavaScript. Now I'm pretty sure the `business logic' of POPFile, which is currently written in Perl, can be ported to JavaScript without too much trouble. The end result: an interface in Gmail that tags incoming messages and quickly allows you to check for and correct mistakes, training it, and bringing the convenience of automatic Bayesian classification to Gmail. Anybody up for it?
What POPFile does
OK first of all, you're asking why would you want some software like POPFile to classify emails for you when you can just set up filters in your email program to do that based on who they're from, what the subject is, and so on? The reason is your email client's filters are static: they do not learn about new family members who are sending you email, nor about new correspondents from your workplace, nor about new junk mailers you have to deal with all the time. In fact, programs like Thunderbird already have Bayesian filtering to deal with this problem of continually-changing junk mails -- it's just that POPFile goes one step further, to try to identify your mails as belonging to arbitrary categories that you set up.
The idea is, once you've set up POPFile to recognise email from your family, from your work, and from your stamp collecting buddies, it will correctly identify these different types of emails, say, about 99.99% of the time. The rest of the time, which is presumably a piffling amount of time, you'll be telling POPFile something like `no, this isn't junk, it's just my little brother, mark it as ``Family'' '. And POPFile will continue to learn, using the Bayesian statistical analysis.
So the end result is, you can set up your email programs to put email marked `Work' in the right folder, and so on, without having to worry about updating your filters all the time.
Now here's my question: why should email program users get these benefits exclusively? Why can't we have something like this for webmail users? Specifically, Gmail users (like me, and it seems half the world nowadays)? Maybe we can. It boils down to three things: Gmail's JavaScript functions, POPFile's statistical categorisation methods, and Firefox's Greasemonkey extension.
What Greasemonkey does
Basically, Greasemonkey allows you to customise Web pages in Firefox in almost unlimited ways with a little JavaScript programming, using that page's Document Object Model and any JavaScript functions defined in it. Check out http://persistent.info/archives/2005/03/01/gmail-searches for an idea about just how powerful Greasemonkey is, and what it can do to Gmail.
I've tried out the above hack, and it actually does work, with a few hiccups. Furthermore, I've tried programming Greasemonkey scripts myself and I can tell you it's a really powerful way of customising websites which you love to make them even more useful. There are actually a ton of scripts people have written out there, and the best place to get them is userscripts.org. Check it out.
POPFile for Gmail?
OK, now we know we can extend Gmail's functionality in amazing ways with Greasemonkey hacks like the one above. Essentially, Greasemonkey is giving us the means to program a user interface for the new Bayesian classification classification features we want in Gmail. Greasemonkey scripts are written in JavaScript. Now I'm pretty sure the `business logic' of POPFile, which is currently written in Perl, can be ported to JavaScript without too much trouble. The end result: an interface in Gmail that tags incoming messages and quickly allows you to check for and correct mistakes, training it, and bringing the convenience of automatic Bayesian classification to Gmail. Anybody up for it?
Oct 19, 2006
The Trojan War was never this good
Read Dan Simmons' Ilium and Olympos a couple of months ago, but haven't gotten round to talking about them till now. First of all, it's true that they're actually one book published as two, probably because if they were published in one piece nobody would buy a book that fat, and sales would be half as much as they were with two books instead of one.
Second, the book is not about the gods and Trojans and Greeks of the recreated Trojan war battlefield of far-future Mars; it's really about the future of humanity and what shape it might take. Simmons draws from a lot of literary sources, primarily Shakespeare (The Tempest) but also Proust (stuff I'm not familiar with) and Vernes (i.e. his Time Machine Eloi and Morlocks ideas).
The thing is, the story starts off with the scholic Thomas Hockenberry telling of the recreated war, and it's immediately gripping, especially to a guy like me who grew up reading his sci-fi on one hand and Greek/Norse/Egyptian mythology on the other. It's gripping for all the reasons the original mythologies are gripping -- the heroes and their stories are larger than life, etc. But the Trojan War storyline intercuts with that of the humans on Earth and the Moravecs on Jupiter, which takes the wind out of it somewhat, because you have all these new characters you didn't know before that you have to deal with, and you just want to get back to reading what Achilles did next.
Achilles by the way is the most interesting character in the story and Simmons lavishes him with detailed description, enough to satisfy any geek. Achilles the man-killer, Achilles the god-killer, Achilles the fleet-footed, Achilles this, and Achilles that. For some reason I kept imagining Brad Pitt as Achilles throughout the story, and it fit, right to the end. (But Eric Bana as Hector didn't -- Hector needs a stronger jawline, and a taller, more muscular figure).
The stories do converge, but they approach convergence from different points, and there's a lot of suspense. I won't bother with a detailed analysis of the thing here, but it's definitely enjoyable. I do want to talk about some of Simmons' ideas for the future of humanity though. Humans ten thousand years in the future are a sad, childlike lot, with every need catered to by robot servants and, who don't know how to read because they don't need to, and spend most of their time partying and pursuing other pleasures. Sounds perfect, but there's no intellectual stuff, no advanced thought. Simmons has a characters in the books disparagingly refer to them as `post-literate'. Ouch.
But these Eloi do have an interesting feature: they have been genetically modified to contain a hundred cybernetic functions, like a map/locator function that projects holographic images of the person being located; body status query functions; and advanced stuff like infonet access, the infonet being a semi-conscious web of information evolved from the internet which now blankets the planet. This infonet is extremely powerful -- it contains a huge amount of data, like information about every molecule in every cell of a tree the infonet user might be looking at. It's described as being totally overwhelming. You see the information, but you don't understand most of the knowledge contained in it. Oh, and you activate these functions by visualising combinations of coloured geometric shapes in your mind's eye. At least, until you can do it without thinking.
The `old-style', Earth-human protagonists introduced have a destiny to fulfill -- to recover the ability to use these advanced functions and recover the technological knowledge lost to the human race. But that's about it. There is some stuff about recovering some ten thousand humans encoded in a tachyon beam orbiting the Earth, but that's just another problem in the myriad collection of problems and mysteries the humans are faced with.
The infonet plays a large part in the book, actually -- combined with some really wild interpretations of quantum theory and post-human technology. It's a good read, but I still think the Trojan War part of the story should have been a different story altogether -- or rather, the story of the old-style humans on Earth should have been a different story, say The Final Fax. The Trojan War parts of the books would have made a kick-ass movie -- especially Achilles' visit to the pit of Tartarus in Hades, in the presence of the original Greek gods, the Titans, imprisoned there by Zeus.
Oct 17, 2006
If only they used this instead of E-Views
(Interesting note: just found out that the Cochrane behind the famous Cochrane-Orcutt method was at Monash, http://www.buseco.monash.edu.au/depts/ebs/.).
We started doing the basics of econometrics -- things like regression and ANOVA -- in Excel last year, but moved to E-Views this semester to do more advanced stuff like time-series analysis. That's too bad, because there's a much better program we can use: R (http://www.r-project.org/). The main reason is it's free -- we can download and use it at home, so we don't have to depend on the computer labs being open and free to get our assignments done. Here's a good article that talks about why R is great: http://jackman.stanford.edu/papers/download.php?i=22.
And yes, I know R is mostly command line and teaching it at Monash would take up too much of our time, taking our focus away from the econometrics theory. But R can be customised and tailored to the Monash courses with a little effort; and it has a Tcl/Tk widget set built-in which can be used to implement graphical versions of the stuff they teach us using E-Views -- things like restricted model F tests (Wald tests), AR(1) estimation, weighted OLS estimation, things like that.
That said, I'm still learning R and it's sometimes been frustrating to try matching my results on time series data to what my textbook, Wooldridge, says I should get. Things like ARMA(p, q) estimation seem to be built in to non-obvious places like the gls function in the nlme package. But it works, for the most part. Using Excel after R -- especially R's matrix handling -- feels like going backwards now.
Sep 13, 2006
Uptime on Windows
Here's a VBScript script which runs in the Windows Scripting Host and shows you how long your computer has been running:
Save it as a VBS file and try running it. Because it runs in the Windows Scripting Host, the uptime script can (generally) be run just by double-clicking on the file in Windows. If that doesn't work, somehow Windows' connection between the VBS file format and the WScript.exe program has been severed, and you'll have to run WScript.exe with the script name as an argument.
The script is basically my current fascination with the Windows scripting environment. There's a lot of documentation available, especially the Microsoft Windows 2000 Scripting Guide, which has been the most useful to me in understanding Windows' built-in scripting architecture.
Other ideas on what to do with this tool are kind of floating around in my head right now: using it to automatically download and tabulate exchange rates from Yahoo, then analysing the data with Excel; recording system uptime and usage statistics like how often and how long I use the computer; creating a script to quickly log in to Windows (Live?) Messenger and send a message to someone; rewriting the sparklines document in straight VBScript to run in the Windows Scripting Host environment, instead of having to open up the sparklines.doc document every time I want to create some sparklines.
All pretty cool ideas, at least from my point of view. And beyond them I might even look into accessing the Windows common controls and trying to create real graphical programs using just WSH. But that's in the far future.
strComputer = "."
Set objWMIService = GetObject("winmgmts:\\" & strComputer & "\root\cimv2")
Set colOses = objWMIService.ExecQuery("SELECT LastBootUpTime From Win32_OperatingSystem")
For Each objOs In colOses
diffMin = DateDiff("n", wmiDateStringToDate(objOs.LastBootUpTime), Now)
diffDays = Fix(diffMin / (60 * 24))
diffMin = diffMin - diffDays * 24 * 60
If diffDays >= 1 Then
uptimeStr = uptimeStr & CStr(diffDays) & "d "
End If
diffHours = Fix(diffMin / 60)
diffMin = diffMin - diffHours * 60
If diffHours >= 1 Then
uptimeStr = uptimeStr & CStr(diffHours) & "h "
End If
If diffMin >= 1 Then
uptimeStr = uptimeStr & CStr(diffMin) & "min"
End If
WScript.Echo "Uptime: " & uptimeStr
Next
Function wmiDateStringToDate(dtmDate)
wmiDateStringToDate = CDate(Mid(dtmDate, 5, 2) & "/" & Mid(dtmDate, 7, 2) & "/" & Left(dtmDate, 4) & " " & Mid (dtmDate, 9, 2) & ":" & Mid(dtmDate, 11, 2) & ":" & Mid(dtmDate, 13, 2))
End Function
Save it as a VBS file and try running it. Because it runs in the Windows Scripting Host, the uptime script can (generally) be run just by double-clicking on the file in Windows. If that doesn't work, somehow Windows' connection between the VBS file format and the WScript.exe program has been severed, and you'll have to run WScript.exe with the script name as an argument.
The script is basically my current fascination with the Windows scripting environment. There's a lot of documentation available, especially the Microsoft Windows 2000 Scripting Guide, which has been the most useful to me in understanding Windows' built-in scripting architecture.
Other ideas on what to do with this tool are kind of floating around in my head right now: using it to automatically download and tabulate exchange rates from Yahoo, then analysing the data with Excel; recording system uptime and usage statistics like how often and how long I use the computer; creating a script to quickly log in to Windows (Live?) Messenger and send a message to someone; rewriting the sparklines document in straight VBScript to run in the Windows Scripting Host environment, instead of having to open up the sparklines.doc document every time I want to create some sparklines.
All pretty cool ideas, at least from my point of view. And beyond them I might even look into accessing the Windows common controls and trying to create real graphical programs using just WSH. But that's in the far future.
May 2, 2006
Live word count script for OpenOffice.org
UPDATE 9 Sep 2010: Did something I've been meaning to do for a while and wrote up an awesome wiki intro for the Live Word Count script in its new BitBucket home: http://bitbucket.org/yawaramin/oo.o-live-word-count/wiki/Home. As a consequence, I'm removing all the duplicate installation and usage instructions from this page. Please check out the BitBucket wiki--that's where all the action is!
UPDATE 17 Mar 2010: Moved script to new home at BitBucket, in case I need to make any further changes/improvements. Small fix to make sure script works both when started from the Macro Selector dialog box and from a toolbar button. Oh yeah, to add a toolbar button to start the macro, see instructions below.
UPDATE 13 Mar 2010: Slight change to wordCount macro to handle being started from a toolbar button.
UPDATE 2 Dec 2009: Confirmed that the script works with OpenOffice.org 3.1.1 on Mac OS X 10.6 (Snow Leopard). As usual, see below for where to put the script in a Mac.
Also, I didn't realise this until now, but I've been cited in Linux Pro Magazine! Yay! :-)
UPDATE 30 May 2009: Just tried the script out again with OpenOffice.org 3.1.0 on Windows Vista; works fine. Please see the paragraph after next for the right place to put this script in Windows.
HERE'S something I worked on a long time ago but am finding very useful, a script or macro which displays a dialog box with a continuously-updating document (or selection) word count.
[...]
Feb 6, 2006
Styling Office XML Documents
This post has been due for several days now. Been doing more research into Office 2003's XML file formats. The primary port of call for all budding Office 2003 XML developers is Office 2003 XML Reference Schemas. This is where you can download the schemas -- the formal descriptions -- and the explanatory documentation on the XML document formats for Word, Excel and others. Another important link is to the page for O'Reilly's new book, Office 2003 XML. There is a download for a sample chapter, Chapter 2: The WordprocessingML Vocabulary. Obviously these are very important references for someone who is just entering the field.
When I posted my last entry, I had already created the style file that tells Word how to display the raw account listing. I just wanted to play around with it a little bit, especially to see if I could get the table formatting right. The formatting as it currently is, is OK; but I wanted to customise it a little bit.
By now I've realised that mastery of tables in WordprocessingML will take some time and (at least) a couple of good references (see links above). So I'll just go ahead with the original plan.
Before I list the actual XSL transformations file that does the magic, I want to actually show its results, to get some oohs and aahs from the audience. Here they are:
OK, here is the XSL style file:
Yeah, whew! That was intense. Mostly though, it was the Word XML markup, which I won't even try to explain now. But for more on WordprocessingML, please check out the latest article at Brian Jones' blog. It's got an excellent mid-level overview.
I've made the XSL instructions bold so you can pick them out clearly and marvel at how few of them there are. (By the way, learned the XSLT at the W3Schools' XSLT Tutorial.) Basically, they say the same thing I described towards the end of my last entry.
Sorry about the underlines in the listing -- have been exploring off-the-top-of-my-head ways to best show listings in HTML, and this is the best compromise I've been able to find between source code editability and web page readability. Will update later if I find anything better. Leave comments with any ideas you might have. Well, got rid of the underlines with some cool new hacks I didn't know about before. Check out the rule for the <pre> tag in my stylesheet.
So what has this exercise accomplished? We see that Word has become, as a result of customers' demands on it, a full-fledged XML transformation and validation engine. With this power, businesses have an amazing new ability to juggle information around, push it into and pull it out of Office documents, change it, and just generally go crazy with it.
I know that the trend in businesslately forever in our age has been to, whenever a new problem is faced, just throw more technology at it. Am I complaining? No way. Bring it on!
When I posted my last entry, I had already created the style file that tells Word how to display the raw account listing. I just wanted to play around with it a little bit, especially to see if I could get the table formatting right. The formatting as it currently is, is OK; but I wanted to customise it a little bit.
By now I've realised that mastery of tables in WordprocessingML will take some time and (at least) a couple of good references (see links above). So I'll just go ahead with the original plan.
Before I list the actual XSL transformations file that does the magic, I want to actually show its results, to get some oohs and aahs from the audience. Here they are:
The account listing as shown by Word when Word has no way of knowing how else to show it.

The account listing with an XSL transformation applied by Word. That is, when the XSL file tells Word how to display it.

OK, here is the XSL style file:
<?xml version="1.0"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:al="http://yawar.blogspot.com">
<xsl:template match="/">
<w:wordDocument xmlns:w="http://schemas.microsoft.com/office/word/2003/wordml" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:sl="http://schemas.microsoft.com/schemaLibrary/2003/core" xmlns:aml="http://schemas.microsoft.com/aml/2001/core" xmlns:wx="http://schemas.microsoft.com/office/word/2003/auxHint" xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:dt="uuid:C2F41010-65B3-11d1-A29F-00AA00C14882" w:macrosPresent="no" w:embeddedObjPresent="no" w:ocxPresent="no" xml:space="preserve">
<o:DocumentProperties>
<o:Title>Account Listing</o:Title>
<o:Author>Yawar Amin</o:Author>
</o:DocumentProperties>
<w:fonts>
<w:defaultFonts w:ascii="Times New Roman" w:h-ansi="Times New Roman" w:cs="Times New Roman"/>
</w:fonts>
<w:styles>
<w:style w:type="paragraph" w:default="on" w:styleId="Normal">
<w:name w:val="Normal"/>
<w:rPr>
<wx:font wx:val="Times New Roman"/>
<w:sz w:val="24"/>
<w:sz-cs w:val="24"/>
<w:lang w:val="EN-GB" w:fareast="EN-US" w:bidi="AR-SA"/>
</w:rPr>
</w:style>
<w:style w:type="paragraph" w:styleId="Heading1">
<w:name w:val="heading 1"/>
<wx:uiName wx:val="Heading 1"/>
<w:basedOn w:val="Normal"/>
<w:next w:val="Normal"/>
<w:rsid w:val="00B04D4D"/>
<w:pPr>
<w:pStyle w:val="Heading1"/>
<w:keepNext/>
<w:pBdr>
<w:top w:val="dotted" w:sz="4" wx:bdrwidth="10" w:space="1" w:color="auto"/>
</w:pBdr>
<w:spacing w:before="240" w:after="60"/>
<w:jc w:val="center"/>
<w:outlineLvl w:val="0"/>
</w:pPr>
<w:rPr>
<wx:font wx:val="Times New Roman"/>
<w:b/>
<w:b-cs/>
<w:kern w:val="32"/>
<w:sz w:val="48"/><w:sz-cs w:val="48"/>
</w:rPr>
</w:style>
<w:style w:type="table" w:styleId="MyTableContemporary">
<w:name w:val="My Table Contemporary"/>
<w:basedOn w:val="TableNormal"/>
<w:rPr>
<wx:font wx:val="Times New Roman"/>
</w:rPr>
<w:tblPr>
<w:tblInd w:w="0" w:type="dxa"/>
<w:tblBorders>
<w:insideH w:val="single" w:sz="18" wx:bdrwidth="45" w:space="0" w:color="FFFFFF"/>
<w:insideV w:val="single" w:sz="18" wx:bdrwidth="45" w:space="0" w:color="FFFFFF"/>
</w:tblBorders>
<w:tblCellMar>
<w:top w:w="0" w:type="dxa"/>
<w:left w:w="108" w:type="dxa"/>
<w:bottom w:w="0" w:type="dxa"/>
<w:right w:w="108" w:type="dxa"/>
</w:tblCellMar>
</w:tblPr>
<w:tblStylePr w:type="firstRow">
<w:rPr>
<w:b/>
<w:b-cs/>
<w:color w:val="auto"/>
</w:rPr>
<w:tblPr/>
<w:tcPr>
<w:tcBorders>
<w:tl2br w:val="none" w:sz="0" wx:bdrwidth="0" w:space="0" w:color="auto"/>
<w:tr2bl w:val="none" w:sz="0" wx:bdrwidth="0" w:space="0" w:color="auto"/>
</w:tcBorders>
<w:shd w:val="pct-20" w:color="000000" w:fill="FFFFFF" wx:bgcolor="F2F2F2"/>
</w:tcPr>
</w:tblStylePr>
<w:tblStylePr w:type="band1Horz">
<w:rPr>
<w:color w:val="auto"/>
</w:rPr>
<w:tblPr/>
<w:tcPr>
<w:tcBorders>
<w:tl2br w:val="none" w:sz="0" wx:bdrwidth="0" w:space="0" w:color="auto"/>
<w:tr2bl w:val="none" w:sz="0" wx:bdrwidth="0" w:space="0" w:color="auto"/>
</w:tcBorders>
<w:shd w:val="pct-5" w:color="000000" w:fill="FFFFFF" wx:bgcolor="FFFFFF"/>
</w:tcPr>
</w:tblStylePr>
<w:tblStylePr w:type="band2Horz">
<w:rPr>
<w:color w:val="auto"/>
</w:rPr>
<w:tblPr/>
<w:tcPr>
<w:tcBorders>
<w:tl2br w:val="none" w:sz="0" wx:bdrwidth="0" w:space="0" w:color="auto"/>
<w:tr2bl w:val="none" w:sz="0" wx:bdrwidth="0" w:space="0" w:color="auto"/>
</w:tcBorders>
<w:shd w:val="pct-20" w:color="000000" w:fill="FFFFFF" wx:bgcolor="F2F2F2"/>
</w:tcPr>
</w:tblStylePr>
</w:style>
</w:styles>
<w:docPr>
<w:view w:val="print"/>
<w:zoom w:percent="100"/>
<w:doNotEmbedSystemFonts/>
<w:validateAgainstSchema/>
<w:saveInvalidXML w:val="off"/>
<w:ignoreMixedContent w:val="off"/>
<w:alwaysShowPlaceholderText w:val="off"/>
</w:docPr>
<w:body>
<wx:sect>
<w:sectPr>
<w:pgSz w:w="11909" w:h="16834" w:orient="portrait" w:code="9"/>
</w:sectPr>
<w:p>
<w:pPr>
<w:pStyle w:val="Heading1"/>
</w:pPr>
<w:r>
<w:t>ACCOUNT LISTING</w:t>
</w:r>
</w:p>
<w:p></w:p>
<w:tbl>
<w:tblPr>
<w:tblStyle w:val="MyTableContemporary"/>
<w:tblW w:w="5000" w:type="pct"/>
<w:tblLook w:val="01E0"/>
</w:tblPr>
<w:tblGrid>
<w:gridCol w:w="2832"/>
<w:gridCol w:w="3238"/>
<w:gridCol w:w="2089"/>
<w:gridCol w:w="3061"/>
</w:tblGrid>
<w:tr>
<w:tc>
<w:p>
<w:pPr>
<w:jc w:val="right"/>
</w:pPr>
<w:r>
<w:t>Account ID</w:t>
</w:r>
</w:p>
</w:tc>
<w:tc>
<w:p>
<w:r>
<w:t>Holder Name</w:t>
</w:r>
</w:p>
</w:tc>
<w:tc>
<w:p>
<w:pPr>
<w:jc w:val="right"/>
</w:pPr>
<w:r>
<w:t>Balance</w:t>
</w:r>
</w:p>
</w:tc>
<w:tc>
<w:p>
<w:r>
<w:t>Debit/Credit</w:t>
</w:r>
</w:p>
</w:tc>
</w:tr>
<xsl:for-each select="al:accountlist/al:account">
<xsl:sort select="al:holdername"/>
<w:tr>
<w:tc>
<w:p>
<w:pPr>
<w:jc w:val="right"/>
</w:pPr>
<w:r>
<w:t><xsl:value-of select="al:accid"/></w:t>
</w:r>
</w:p>
</w:tc>
<w:tc>
<w:p>
<w:r>
<w:t><xsl:value-of select="al:holdername"/></w:t>
</w:r>
</w:p>
</w:tc>
<w:tc>
<w:p>
<w:pPr>
<w:jc w:val="right"/>
</w:pPr>
<w:r>
<w:t><xsl:value-of select="al:balance"/></w:t>
</w:r>
</w:p>
</w:tc>
<w:tc>
<w:p>
<w:r>
<w:t><xsl:value-of select="al:drcr"/></w:t>
</w:r>
</w:p>
</w:tc>
</w:tr>
</xsl:for-each>
</w:tbl>
</wx:sect>
</w:body>
</w:wordDocument>
</xsl:template>
</xsl:stylesheet>
Yeah, whew! That was intense. Mostly though, it was the Word XML markup, which I won't even try to explain now. But for more on WordprocessingML, please check out the latest article at Brian Jones' blog. It's got an excellent mid-level overview.
I've made the XSL instructions bold so you can pick them out clearly and marvel at how few of them there are. (By the way, learned the XSLT at the W3Schools' XSLT Tutorial.) Basically, they say the same thing I described towards the end of my last entry.
So what has this exercise accomplished? We see that Word has become, as a result of customers' demands on it, a full-fledged XML transformation and validation engine. With this power, businesses have an amazing new ability to juggle information around, push it into and pull it out of Office documents, change it, and just generally go crazy with it.
I know that the trend in business
Feb 1, 2006
Sparklines, internship ends, MS Office XML documents
In all the furore over my new and continually-evolving design I've been neglectful of my Sparklines code. Well, the good news is I've been working on it so intensively that the current version of sparklines.doc is so much more functional than the code I've posted here that I've seriously been thinking about deleting the code from the last two sparklines entries. But hell, it's amusing to look at.
The bad news is I've been working on even more exciting stuff for the last few days -- like my blog and conversion of the bank's daily reports into parseable XML form -- that the work I'm doing on sparklines.doc has slowed to a crawl. BUT to be fair, it meets my needs fully.
I'll take a brief interlude here and talk about some of the stuff I tried to do during my internship at ONE Bank, Dhanmondi branch. It'll lead up directly to why I'm so hyped-up about MS Office's new XML file format -- and this is weird, because just a few days ago I'd have told you OpenOffice.org's XML file format is better than Microsoft's. Now I'm strongly inclined to say otherwise.
At the bank, as I (think I) mentioned in Sparklines: can't resist, they have a lot of computer-generated output put in their hard drives daily. I guess their database-querying and -reporting software is tasked to process the day's transactions and output reports on the states of the various accounts, clients and such, every night. Now these reports are in plain-text format and currently the people in my branch, whenever they need to look up some information, just open up the report files in Wordpad and do a search for it.
This simple searching of plain-text files is well and good for small-scale information needs like looking up the account number of an account holder who can't recall the number, finding the interest rates offered on different types of deposits and loans, and sometimes also finding out historical interest rates. But it quickly starts sucking up your time if you have to keep doing things like:
The common theme running through all of these different tasks is: the user has to process information output from the central database(s) in different ways and create documents showing these data in a nicely formatted way. And this has to be done month after month, with a lot of the document staying basically the same -- the changing data being the newly-processed information.
To me, the processes above are screaming to be automated. And this is where Office's new XML file formats come in. From what I've read about Office's (2003 and above) capabilities in Brian Jones' blog, Word lets you define arbitrary arrangements for your data and then lets you tell it how to format and display the data. This is done through the magic of XML schemas and stylesheets. For details, check out the article. But in short, suppose you start out with some raw data you're working on, information about about some accounts:
You have this data in XML format, obviously ideal because of its parseability to both humans and computers. Say, this is your XML:
Now, you need a way to tell Word (or any other XML-processing program) what kind of values to expect in each field so that it doesn't goof up on bad data: the account ID should be a sequence of ten digits; the name should be a string; the balance a real number (greater than zero), and the Debit/Credit field should be either `Dr' or `Cr', and nothing else. In fact, we could really just use `d' and `c', but Dr and Cr are time-honoured abbreviations of the words. Turns out the way to do is is through another XML file, a schema definition file.
The schema definition for our account listing should be something like:
Yes, it looks rather daunting, but it's not that hard; I whipped this schema up myself browsing through W3Schools' Schema tutorials.
The last piece of the puzzle is, how do we tell Word how to format and display our nice XML file? The answer is the standardised XML Stylesheet Language, XSL. Yet another piece of XML coding, this file instructs Word on how to create a Word XML document on-the-fly from the XML data file that you have (the accounts listing file). Let me try a whimsical explanation here. Imagine the stylesheet file is talking to Word, giving running instructions as the input file is being processed.
`Started reading the document? OK, write the heading, ``ACCOUNT LISTING''. Format it with the ``Heading 1'' style. Now leave a blank line and start a four-column table, with column headers ``Account ID'', ``Holder Name'', ``Balance'' and ``Debit/Credit''.
`Now for each <account>, create a new table row, and: put the contents of the <accid> in the first column; the contents of the <holdername> in the second column; <balance> in the third; and <drcr> in the fourth. Oh, and sort the table rows by account holder name.'
And remember, this is a Word document that is being created -- not an HTML file. Yeah, you can do all that with XSL inside Word!
Soon, I'll post the stylesheet file I've created to do the transformation, and hopefully graphical comparisons of the different views of the same XML document.
The bad news is I've been working on even more exciting stuff for the last few days -- like my blog and conversion of the bank's daily reports into parseable XML form -- that the work I'm doing on sparklines.doc has slowed to a crawl. BUT to be fair, it meets my needs fully.
I'll take a brief interlude here and talk about some of the stuff I tried to do during my internship at ONE Bank, Dhanmondi branch. It'll lead up directly to why I'm so hyped-up about MS Office's new XML file format -- and this is weird, because just a few days ago I'd have told you OpenOffice.org's XML file format is better than Microsoft's. Now I'm strongly inclined to say otherwise.
At the bank, as I (think I) mentioned in Sparklines: can't resist, they have a lot of computer-generated output put in their hard drives daily. I guess their database-querying and -reporting software is tasked to process the day's transactions and output reports on the states of the various accounts, clients and such, every night. Now these reports are in plain-text format and currently the people in my branch, whenever they need to look up some information, just open up the report files in Wordpad and do a search for it.
This simple searching of plain-text files is well and good for small-scale information needs like looking up the account number of an account holder who can't recall the number, finding the interest rates offered on different types of deposits and loans, and sometimes also finding out historical interest rates. But it quickly starts sucking up your time if you have to keep doing things like:
- prepare a monthly report on deposit mobilisation -- that is, a tally of the people who opened and closed deposit accounts, along with their account balances, and total amount of money deposited and withdrawn thus;
- prepare reports with tallies of amounts grouped by type (deposit/loan), interest rate, and then economic sector code, as required by Bangladesh Bank;
- prepare credit risk grading reports;
- create mass-mailings to send out to account-holders and prospective clients;
- email daily lists of transactions to the companies with which the bank has bill-collection arrangements;
- and many more types of documents that the employees of each branch routinely have to prepare.
The common theme running through all of these different tasks is: the user has to process information output from the central database(s) in different ways and create documents showing these data in a nicely formatted way. And this has to be done month after month, with a lot of the document staying basically the same -- the changing data being the newly-processed information.
To me, the processes above are screaming to be automated. And this is where Office's new XML file formats come in. From what I've read about Office's (2003 and above) capabilities in Brian Jones' blog, Word lets you define arbitrary arrangements for your data and then lets you tell it how to format and display the data. This is done through the magic of XML schemas and stylesheets. For details, check out the article. But in short, suppose you start out with some raw data you're working on, information about about some accounts:
| Account ID | Holder Name | Balance | Debit/Credit |
|---|---|---|---|
| 1234567890 | Mr X | 100000 | Cr |
| 2345678901 | Ms Y | 96000 | Cr |
| 3456789012 | Dr Z | 45009.87 | Dr |
You have this data in XML format, obviously ideal because of its parseability to both humans and computers. Say, this is your XML:
<?xml version="1.0"?>
<?mso-application progid="Word.Document"?>
<al:accountlist xmlns:al="http://yawar.blogspot.com">
<al:account>
<al:accid>1234567890</al:accid>
<al:holdername>Mr X</al:holdername>
<al:balance>100000</al:balance>
<al:drcr>Cr</al:drcr>
</al:account>
<al:account>
<al:accid>2345678901</al:accid>
<al:holdername>Ms Y</al:holdername>
<al:balance>96000</al:balance>
<al:drcr>Cr</al:drcr>
</al:account>
<al:account>
<al:accid>3456789012</al:accid>
<al:holdername>Dr Z</al:holdername>
<al:balance>45009.87</al:balance>
<al:drcr>Dr</al:drcr>
</al:account>
</al:accountlist>
Now, you need a way to tell Word (or any other XML-processing program) what kind of values to expect in each field so that it doesn't goof up on bad data: the account ID should be a sequence of ten digits; the name should be a string; the balance a real number (greater than zero), and the Debit/Credit field should be either `Dr' or `Cr', and nothing else. In fact, we could really just use `d' and `c', but Dr and Cr are time-honoured abbreviations of the words. Turns out the way to do is is through another XML file, a schema definition file.
More about schemas at MSDN's Advanced XML Support in Word and the W3C's XML Schema Primer.
Schema generator at XSD Inference Demo.
More tools, including one that validates your XML file against its schema, at XML Tools.
More tools, including one that validates your XML file against its schema, at XML Tools.
The schema definition for our account listing should be something like:
<?xml version="1.0"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://yawar.blogspot.com"
xmlns:al="http://yawar.blogspot.com"
elementFormDefault="qualified">
<xsd:element name="accountlist" />
<xsd:complexType>
<xsd:sequence>
<xsd:element name="account" minOccurs="1" maxOccurs="unbounded">
<xsd:complexType>
<xsd:all>
<xsd:element name="accid">
<xsd:simpleType>
<xsd:restriction base="xsd:string">
<xsd:pattern value="[0-9]{10}" />
</xsd:restriction>
</xsd:simpleType>
</xsd:element>
<xsd:element name="holdername" type="xsd:string" />
<xsd:element name="balance">
<xsd:simpleType>
<xsd:restriction base="xsd:decimal">
<xsd:minInclusive value="0" />
</xsd:restriction>
</xsd:simpleType>
</xsd:element>
<xsd:element name="drcr">
<xsd:simpleType>
<xsd:restriction base="xsd:string">
<xsd:pattern value="[DC]r" />
</xsd:restriction>
</xsd:simpleType>
</xsd:element>
</xsd:all>
</xsd:complexType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:schema>
Yes, it looks rather daunting, but it's not that hard; I whipped this schema up myself browsing through W3Schools' Schema tutorials.
The last piece of the puzzle is, how do we tell Word how to format and display our nice XML file? The answer is the standardised XML Stylesheet Language, XSL. Yet another piece of XML coding, this file instructs Word on how to create a Word XML document on-the-fly from the XML data file that you have (the accounts listing file). Let me try a whimsical explanation here. Imagine the stylesheet file is talking to Word, giving running instructions as the input file is being processed.
`Started reading the document? OK, write the heading, ``ACCOUNT LISTING''. Format it with the ``Heading 1'' style. Now leave a blank line and start a four-column table, with column headers ``Account ID'', ``Holder Name'', ``Balance'' and ``Debit/Credit''.
`Now for each <account>, create a new table row, and: put the contents of the <accid> in the first column; the contents of the <holdername> in the second column; <balance> in the third; and <drcr> in the fourth. Oh, and sort the table rows by account holder name.'
And remember, this is a Word document that is being created -- not an HTML file. Yeah, you can do all that with XSL inside Word!
As an aside, for someone like me, who cut his teeth on LaTeX and then a little bit of DocBook (SGML and XML) with PassiveTeX, Jade, Apache FOP, you name it, Word's new XML capabilities just blow me away. It looks like Word has become the powerful XML processing and transformation engine that documentation writers have always dreamed of.
Soon, I'll post the stylesheet file I've created to do the transformation, and hopefully graphical comparisons of the different views of the same XML document.
Jan 26, 2006
The Wheel of Time -- The Eye of the World
Wheeling Round and Round
Finished Robert Jordan's The Eye of the World and it was a whopper. The story itself is 782 pages. Not the longest I've read, but remarkable because the whole book is nothing more than a setup, even a leaflet, for the rest of the series. And wheels within wheels: almost the whole of the book is a setup for the last couple of chapters, where it really gets exciting.
The book as a whole is a long journey, a long series of hair-breadth escapes, interspersed with threatening dreams, drawn out but at the same time picking up more and more pace, until the explosive ending. The ending makes you want to go out and get the next book pretty much immediately.
But that's not the first thing that struck me, by far, while I was reading it. That would be the similarities to Tolkien's Lord of the Rings. Here are a basic few:
Anyway, I do appreciate that there are definitely big differences. Jordan writes in more modern prose, with more short, sharp sentences for dramatic effect. Short. Dramatic. And he avoids, for the most part, Tolkien's rambling descriptions of this valley here, that nook and cranny there, that seem to go on for days. Oh, and a blessed avoidance of accented characters in names. But they're more than made up for with a liberal dose of apostrophes. Check out the names of some of the main Trolloc tribes (and I've thrown in their roots in monster names): Ahf'frait (afreet), Al'ghol (ghoul), Bhan'sheen (banshee), Dha'vol (devil), Dhai'mon (guess this one), Dhjin'nen (djinn), Ghar'ghael (gargoyle), Ghob'hlin (again, guess), Gho'hlem (golem), Ghraem'lan (gremlin).
But I digress. There is the One Power, a mystical force which comes from the True Source of the universe, drives the eternal Wheel of Time, and empowers a few chosen individuals with great power but at the risk of death and/or madness. But then again, it's like Tolkien's One Ring where it gives you power against the bad guy but the price is high. The real revelation is the turning of the Wheel of Time, where apparently the ages come and go and come again; nothing new ever happens. Civilisations rise and fall, and fall some more, in the eternal battle (you know the one, Good v Evil). Mankind continues to lose science and technology because it just can't get a firm foothold on the Earth before it's all toppled away again. Bleak outlook, really. But then I've heard there are thirteen books in this series, each one presumably as fat as the first. With that kind of length, what else could Jordan be doing but telling the story of the liberation of humanity from the yoke of the Wheel? Guess I'll have to find out. But it's what I would do.
Finished Robert Jordan's The Eye of the World and it was a whopper. The story itself is 782 pages. Not the longest I've read, but remarkable because the whole book is nothing more than a setup, even a leaflet, for the rest of the series. And wheels within wheels: almost the whole of the book is a setup for the last couple of chapters, where it really gets exciting.
The book as a whole is a long journey, a long series of hair-breadth escapes, interspersed with threatening dreams, drawn out but at the same time picking up more and more pace, until the explosive ending. The ending makes you want to go out and get the next book pretty much immediately.
But that's not the first thing that struck me, by far, while I was reading it. That would be the similarities to Tolkien's Lord of the Rings. Here are a basic few:
- Two Rivers = The Shire
- Tam al'Thor = Frodo, brings back `ring' (either Rand or the sword, or both, depending on how you look at it) from his adventures abroad
- Fellowship sets out on quest
- Mischievious Mat Cauthon = Mischevious Pippin Took
- Moiraine = Gandalf
- Lan = Aragorn
- Sauron = Ba'alzamon
- Fades hunting our `hobbits' = Ringwraiths
- Trollocs = orcs
- Padan Fain = Gollum
- Journey to Blight = Trip to Mordor. Pack light, heroes! :-)
- Children of the Light capture Perrin & Egwene = Faramir's gang captures Frodo, Sam & Gollum. OK, this is stretching it a bit
- Green Man = Tom Bombadil, only sadder
- Green Man = Ent
- Egwene sounds like Éowyn
Anyway, I do appreciate that there are definitely big differences. Jordan writes in more modern prose, with more short, sharp sentences for dramatic effect. Short. Dramatic. And he avoids, for the most part, Tolkien's rambling descriptions of this valley here, that nook and cranny there, that seem to go on for days. Oh, and a blessed avoidance of accented characters in names. But they're more than made up for with a liberal dose of apostrophes. Check out the names of some of the main Trolloc tribes (and I've thrown in their roots in monster names): Ahf'frait (afreet), Al'ghol (ghoul), Bhan'sheen (banshee), Dha'vol (devil), Dhai'mon (guess this one), Dhjin'nen (djinn), Ghar'ghael (gargoyle), Ghob'hlin (again, guess), Gho'hlem (golem), Ghraem'lan (gremlin).
But I digress. There is the One Power, a mystical force which comes from the True Source of the universe, drives the eternal Wheel of Time, and empowers a few chosen individuals with great power but at the risk of death and/or madness. But then again, it's like Tolkien's One Ring where it gives you power against the bad guy but the price is high. The real revelation is the turning of the Wheel of Time, where apparently the ages come and go and come again; nothing new ever happens. Civilisations rise and fall, and fall some more, in the eternal battle (you know the one, Good v Evil). Mankind continues to lose science and technology because it just can't get a firm foothold on the Earth before it's all toppled away again. Bleak outlook, really. But then I've heard there are thirteen books in this series, each one presumably as fat as the first. With that kind of length, what else could Jordan be doing but telling the story of the liberation of humanity from the yoke of the Wheel? Guess I'll have to find out. But it's what I would do.
Jan 22, 2006
New style, cont.
After a lot of high-flying coding trying to get cookies to work (to
remember which user has seen which posts and/or comments) and at the
same be compatible with Internet Explorer, I've decided to BAD (Bypass
All Difficulties) and just show the posts and comments by default,
letting users hide them if they want. Code is so much simpler, and at
the same time IE users get to at least read the posts, even if they
don't get the cool clicking and hiding/showing effects.
Jan 19, 2006
New style
After what seems like an eternity with the old ready-made style, have finally gotten down and dirty with Blogger's internals. The inspiration was Gmail's message display interface, which also led me to suggest such an interface for the next version of Thunderbird in the website maintained by the developers, here. Also led me to thinking about how to implement something like it with HTML. Plucked up some courage reading up on JavaScript, the DOM, and CSS, then gave it a try; rather aborted results can be seen here.
Then realised that Blogger's template system provides pseudo-HTML tags which automatically pull blog posts and comments out of the Blogger database -- so basically we have this big database of items which we can pull out and display, rather as if they were emails. Of course, they're a little more complicated than emails (because each post can have one or more comments), which leads to some code complexity; but on the whole it was surprisingly easy. Guess I have XML/CSS/JavaScript and their amazing expressiveness to thank for that.
One thing to note though is that the site doesn't work very well at all on Internet Explorer, even the version 6 that I have running on this XP Service Pack 2 machine. Tried a perfunctory hack to solve the problem, but hasn't worked. Oh well, will tackle it later, I guess. Meanwhile, I recommend all my beloved viewers (anybody out there? :-) use Firefox or Opera, the two best browsers available today.
Then realised that Blogger's template system provides pseudo-HTML tags which automatically pull blog posts and comments out of the Blogger database -- so basically we have this big database of items which we can pull out and display, rather as if they were emails. Of course, they're a little more complicated than emails (because each post can have one or more comments), which leads to some code complexity; but on the whole it was surprisingly easy. Guess I have XML/CSS/JavaScript and their amazing expressiveness to thank for that.
One thing to note though is that the site doesn't work very well at all on Internet Explorer, even the version 6 that I have running on this XP Service Pack 2 machine. Tried a perfunctory hack to solve the problem, but hasn't worked. Oh well, will tackle it later, I guess. Meanwhile, I recommend all my beloved viewers (anybody out there? :-) use Firefox or Opera, the two best browsers available today.
Jan 12, 2006
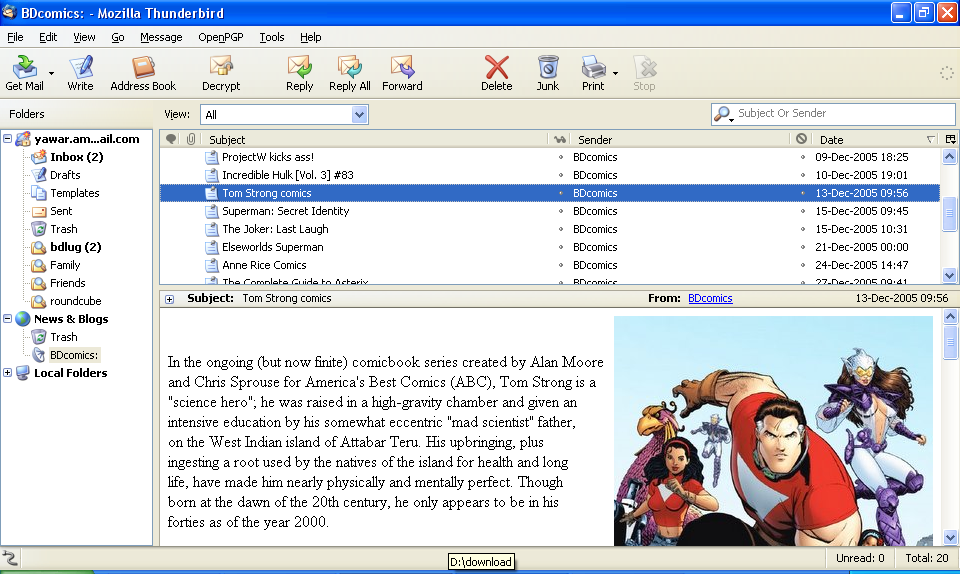
Thunderbird rocks
Set up Thunderbird to handle my Gmail account as well as the ISP-provided POP3 account. Works great and, what's more, allows me to sign and/or encrypt outgoing messages with Thunderbird's Enigmail extension which gives Thunderbird OpenPGP support.
Also set up the BDComics RSS feed (Tools > Account Settings..., then Add Account...), making it a hell of a lot easier to navigate all the great comics links put up there.

Also set up the BDComics RSS feed (Tools > Account Settings..., then Add Account...), making it a hell of a lot easier to navigate all the great comics links put up there.
Subscribe to:
Comments (Atom)
Annoyances
(Score:5, Informative)